Pwn入门系列10——linux动态内存管理机制
什么是堆
(1)堆时程序用于分配动态内存的一段内存区域
(2)它独立的存在与内存中,介于程序内存基地址和libc地址之间。
(3)从低地址向高地址生长
(4)和用户打交道
例子1
(1)一个留言板程序:用户可以输入自己的留言,留言长度由用户决定
(2)我们之前学过,栈上存储的是一个函数的局部变量,bss存储全局变量
(3)那么我们如何存储用户输入的留言呢?
(4)用户的留言有可能是几百个到几千个字符。
解决办法:开一个二维大数组?首先长度会有限制。试想一下,如果每个用户所能支配的最大内存为4096个字节,当用户输入4096个字符时,皆大欢喜,空间内容充分利用。但是用户只输入一个字节,是不是就有4095个字节长度的内存区域被浪费了?如果有很多个用户都输入少于最大字节长度的内存的数据,是不是浪费的内存就更多了呢?而且,用户如果不要了这段内存,该怎么回收呢?
(5)有一种办法能够让程序根据用户需要的内存长度大小来分配内存,并且不需要我们管理内存。
(6)在libc中,我们可以通过malloc(size)来给用户分配一段长度为size的内存,通过free(ptr)来释放这段内存区域。
(7)这些数据,被统一存放在了堆中,维护这些数据的运行机制在glibc中,称之为ptmalloc管理器。
堆内存管理机制
(1)堆的漏洞机制相比于栈十分复杂,有比栈更多的利用方式,利用堆所需要的条件比栈少。
(2)一般情况下栈溢出起码要16个字节,也就是至少溢出到返回地址才能利用,但是堆的话只需要一个字节就可以完成利用,甚至这个字节是个\x00,也就是空字节,nullbyte。
(3)栈的话基本都会关闭一个到两个保护机制,堆的话一般全开。
堆块
①在了解ptmalloc的内存管理机制前,我们先了解一下堆块在内存中的存储形式。
②在内存中,堆是以一个个堆块构成的,这些堆块成为chunk。
③在64位系统中,堆块的大小是8字节对齐的,也就是说,我们申请一个15字节长度的堆块,实际上我们用户手中可控的数据区域为16个字节。
④但是在管理中,一个堆块除了用户数据区外,还有头部字段,头部字段的长度为16字节。同时在64位系统中,一个堆块最小长度为32个字节(包括头部),也就是说,我们分配了1字节的堆块,它的实际长度是32个字节。
如图所示: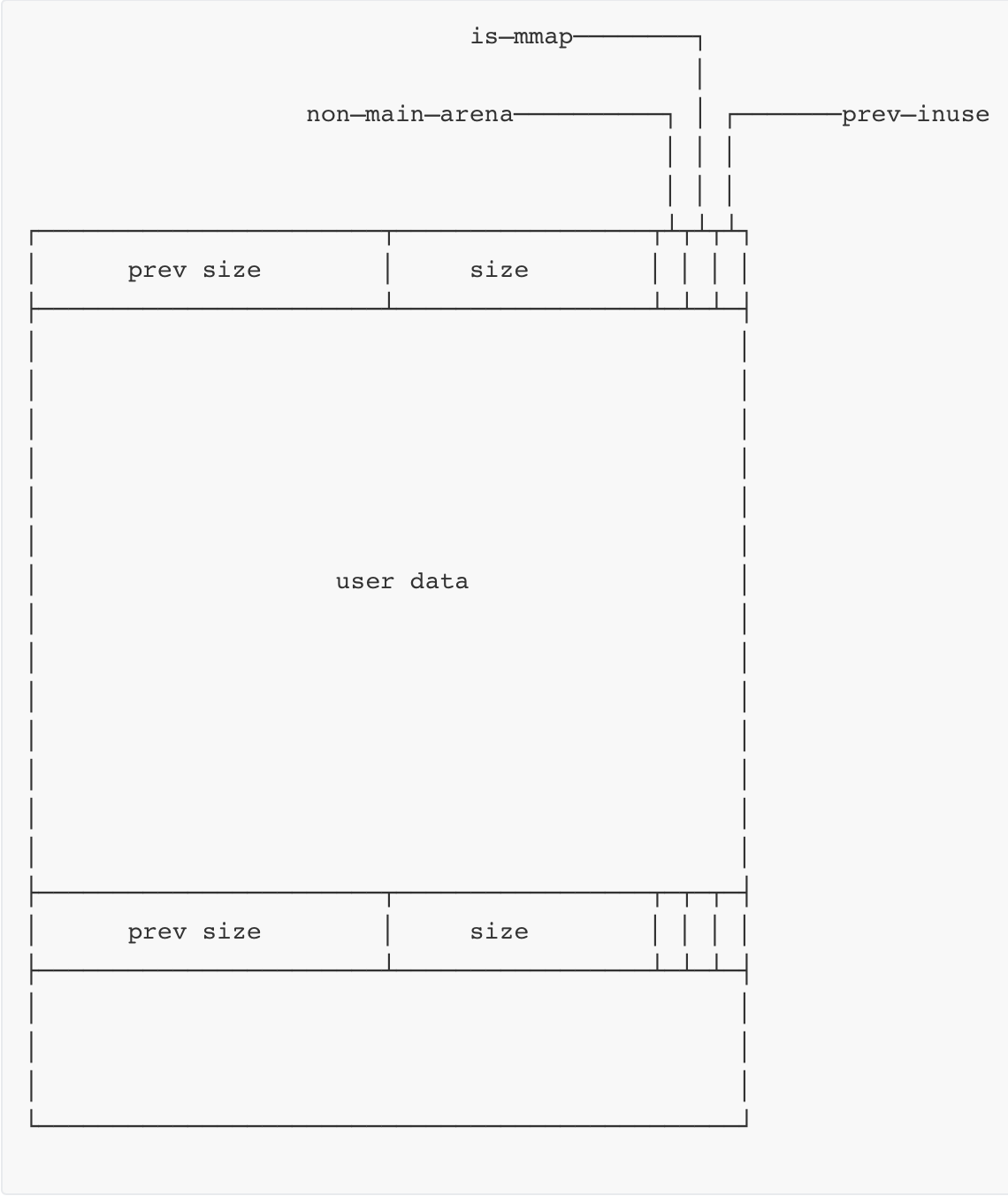
①prev_size 和 size字段分别代表前一个chunk的大小以及当前chunk的大小,大小都是8字节,一共16个字节,称之为chunk的头部字段。
②后面的user data区域是用户可以输入数据的地方。
③chunk的大小8个字节对齐,所以说堆与分配器来说,0x80,0x81,0x82大小的堆块都是一样的,都是0x80大小。
④为了节省空间,将size的最低三个bit设置为三个标志位
⑤从高到低分别为non_main_arena、is_mmap、prev_inuse,non_main_arena用来记录当前chunk是否不属于主线程,1表示不属于,0表示属于;is_mmap表示当前chunk是否是由mmap分配的,1表示属于,0表示不属于;prev_inuse用来表示前面紧邻的那个chunk是否正在使用,0表示被释放,1表示正在被使用。
⑥prevsize记录前面一个chunk的大小,前提是前面的chunk被free掉了才生效,系统才把prev_size字段当做prevsize。那么其他时候这个字段有用吗?没用的话不是浪费了8个字节?有用!如果上一个chunk正在被使用,那么它会把下一个chunk的Prevsize字段当做userdata。充分利用空间。
⑦如果我们申请一个0x80长度大小的区域,系统实际给我们0x90的大小(0x10头部),如果我们申请0x88大小的区域,系统同样会给我们0x90大小的区域(算头部),剩下的8个字节,使用nextchunk的prevsize区域。因为当一个chunk被释放的时候,nextchunk的prevsize才代表一个chunk的大小,所以就是这么设计了。
特殊的堆块topchunk
①最开始时,程序的堆还未被使用,整个的堆区域属于一个很大的堆块叫做topchunk。
②当已经被使用的空间不够时,程序就会从topchunk中分割一块出来使让整个程序使用。
堆块的管理
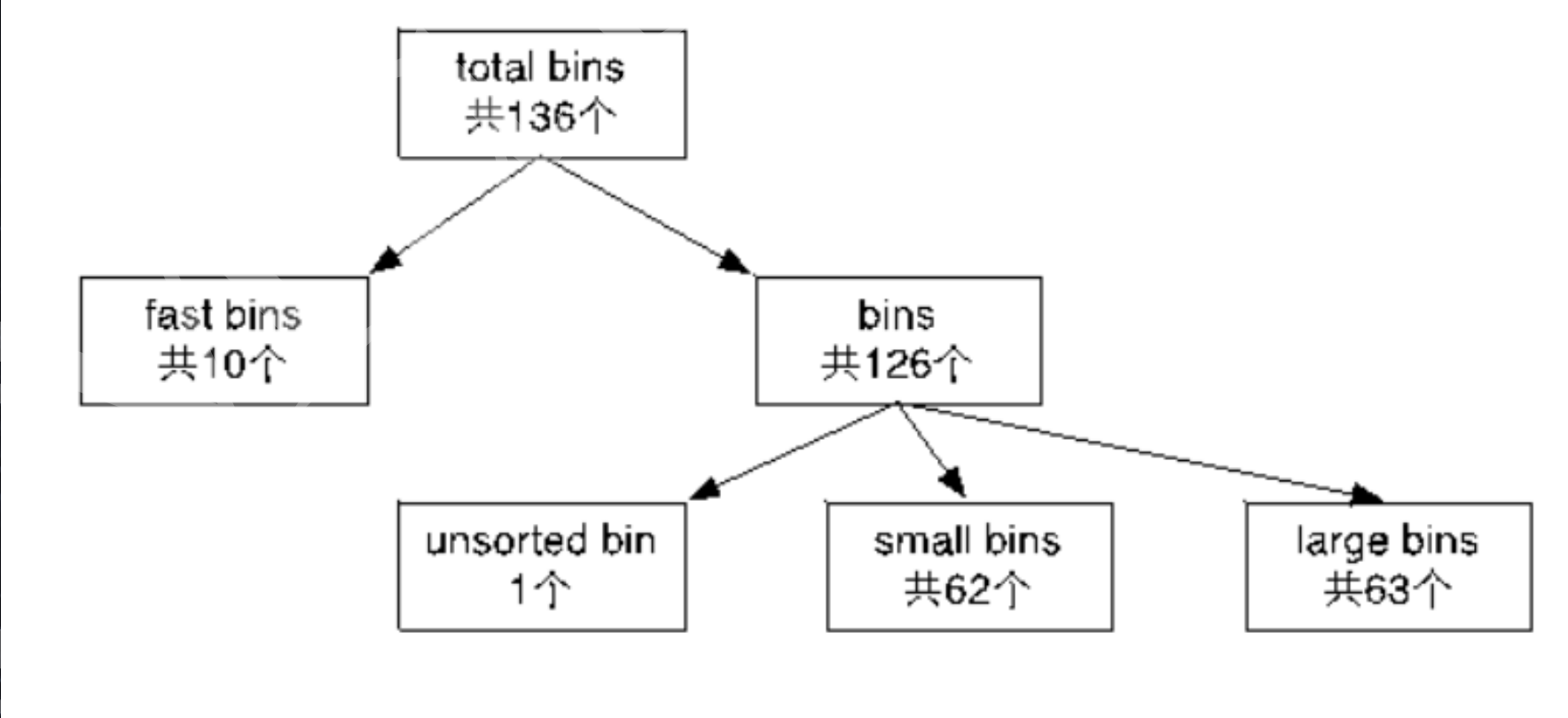
为了保证程序的快速运行,而且方便系统内存管理,所以ptmalloc将释放后的堆块根据其大小分成了不同的bin。
①fastbin:大小范围从0x20-0x80
②smallbin:大小范围从0x90-0x400
③largebin:大小范围在0x410以上
④unsortedbin:未归类的bin,临时存储用,存放的堆块大小不一定。
堆块被free后样子如图: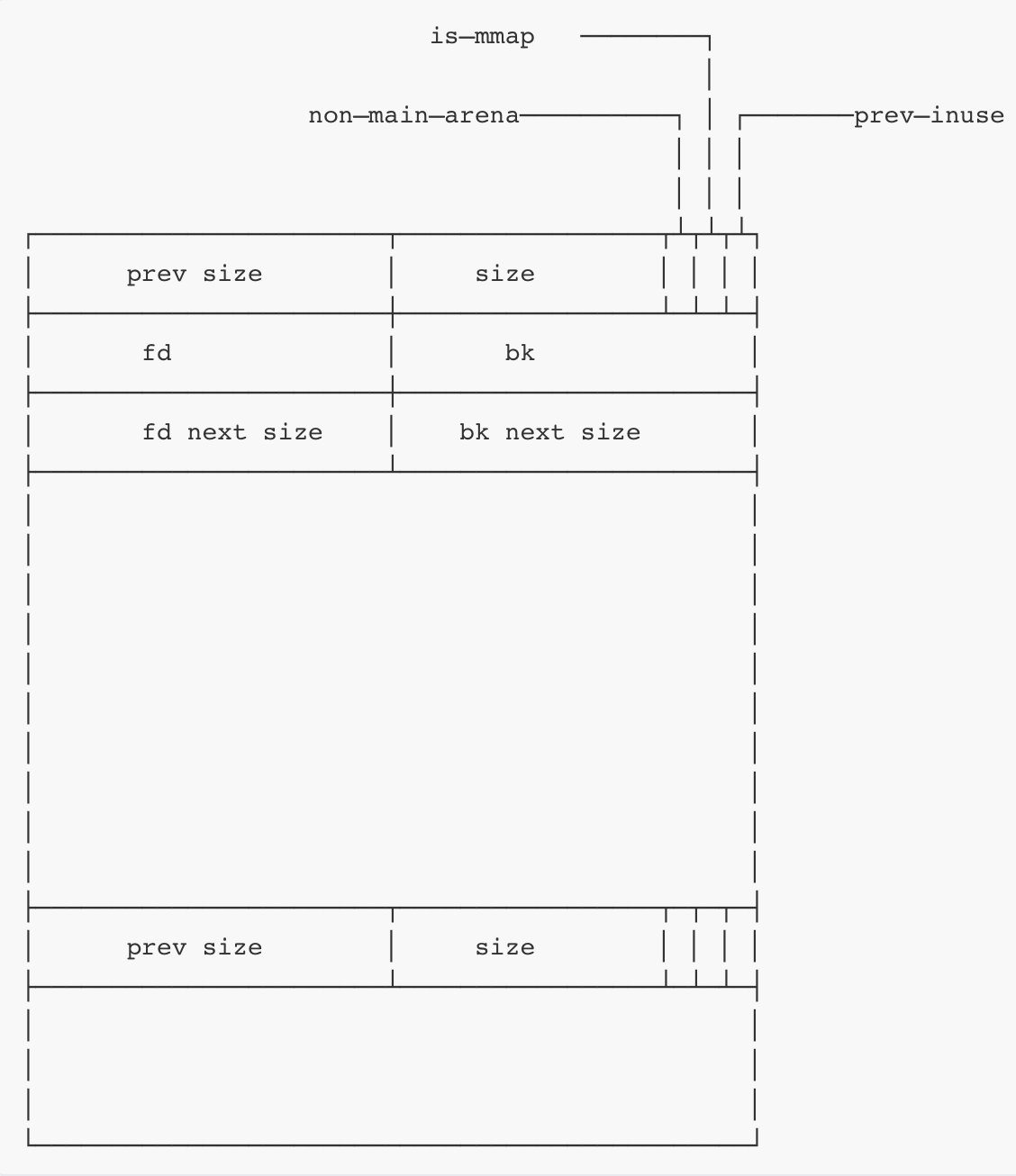
由于chunk被free了,所以按常理说永不不应该能够访问到这个chunk。所以userdata区域存放一些用于管理内存的指针信息。
链表结构
①fastbin:单链表结构,只有fd
②small&unsortedbin:双向链表结构,fd和bk都有
③largebin:双向链表,fd和bk都有,同时还有fdnextsize和bknextsize
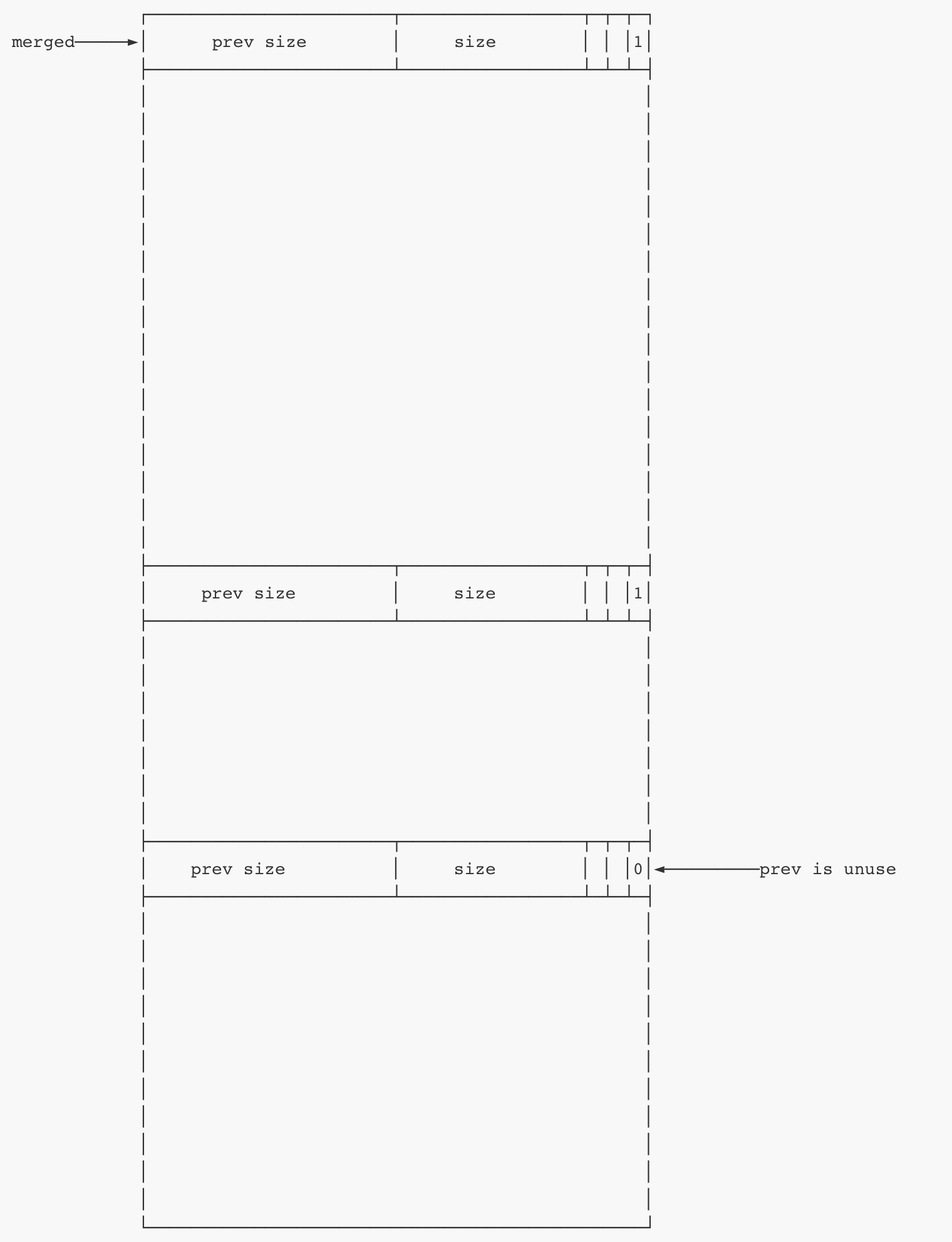
堆块合并
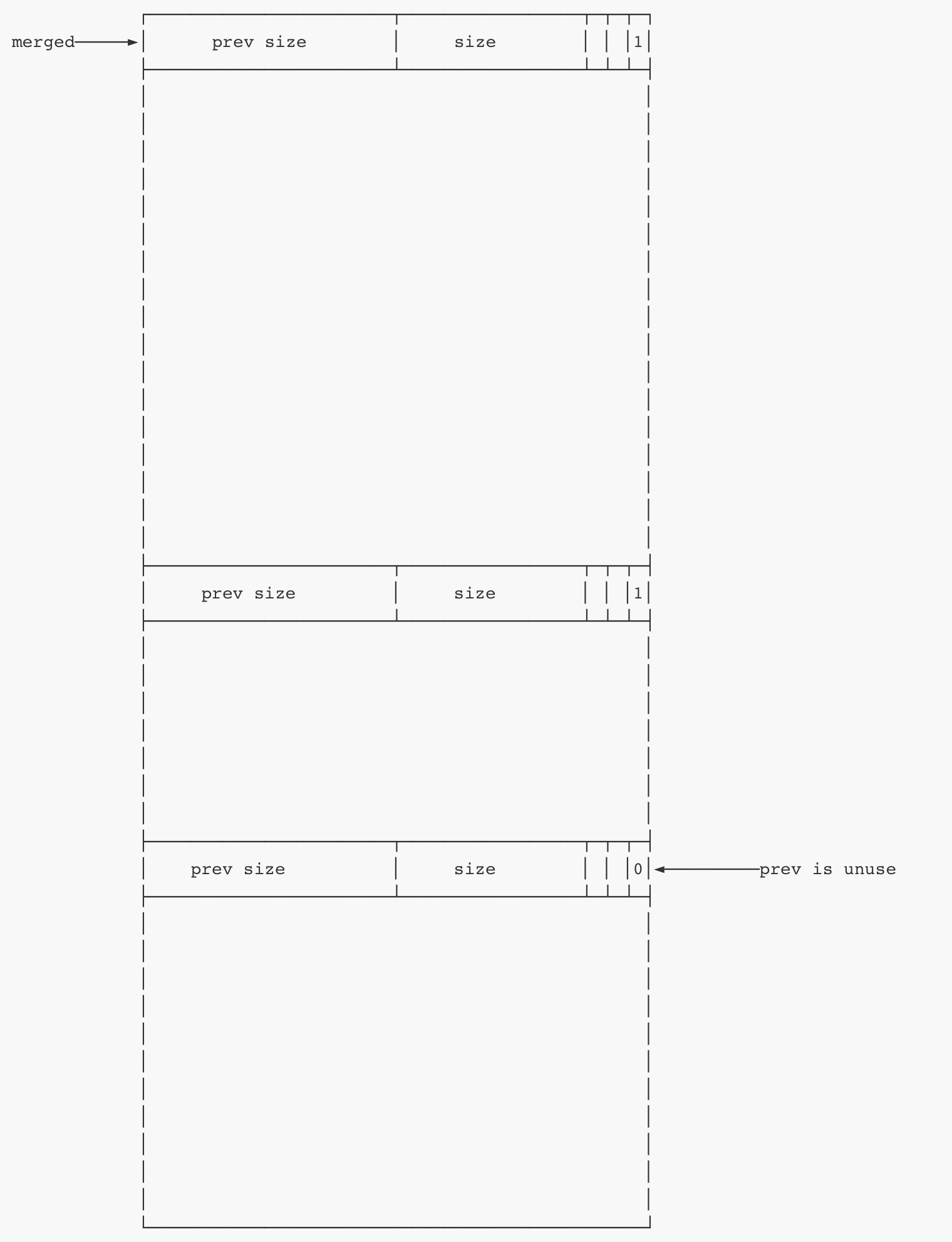
如果我们释放掉了一个堆块,(可能)会出发向前合并和向后合并。
①向前合并:
检查当前chunk的previnuse位,如果为0,则根据当前chunk的prev size找到prev chunk的头部,两个堆块合并。
②向后合并:
检查当前chunk的next nextchunk的prev inuse位(因为一个堆块的状态由它后面chunk的previnuse位决定,所以确定nextchunk的状态需要检查next nextchunk 的previnuse位),然后根据nextchunk的状态决定是否合并。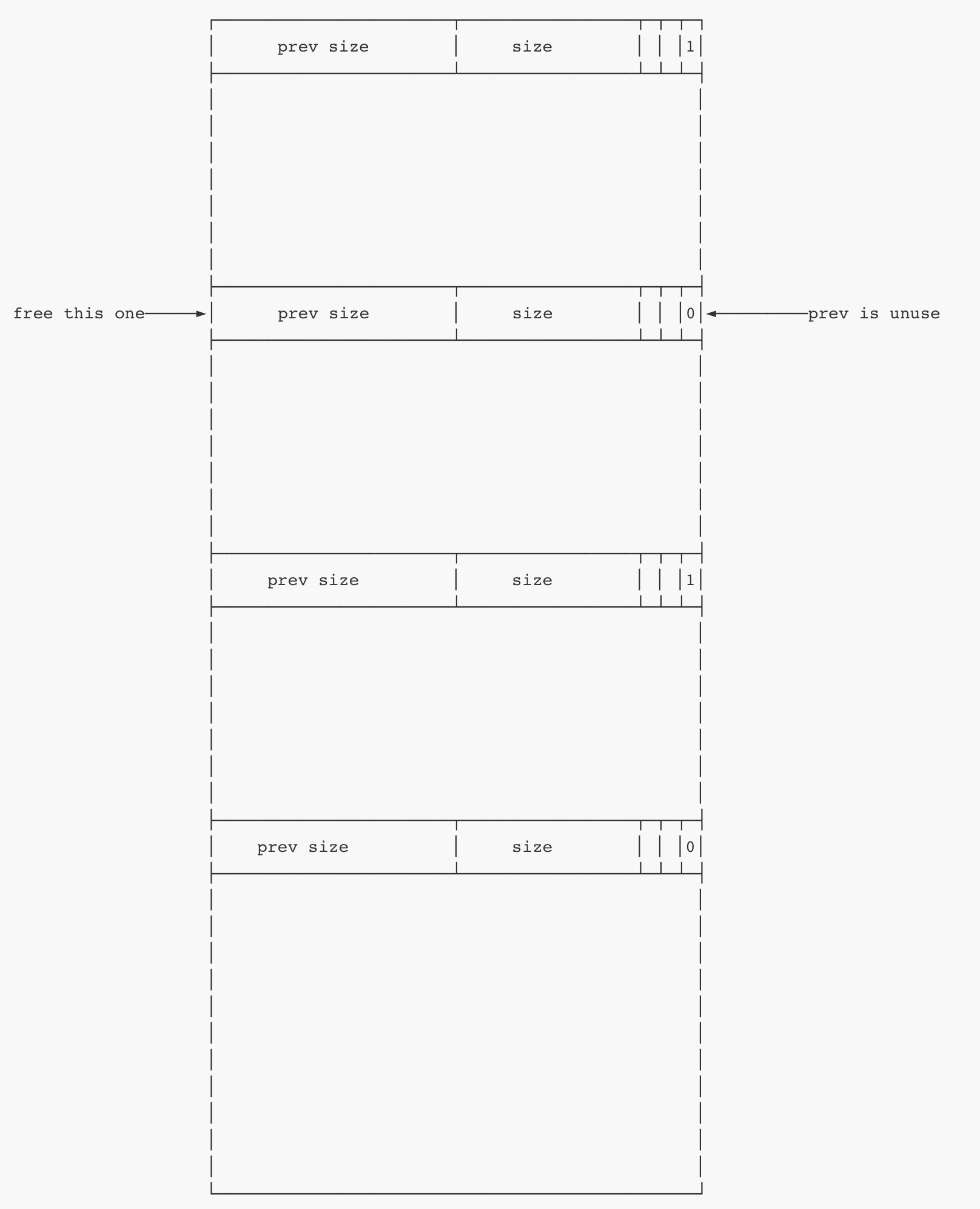

arena
①是一块结构体,用于管理bins。
②主线程创建的arena称之为main_arena,其他的叫threadarena。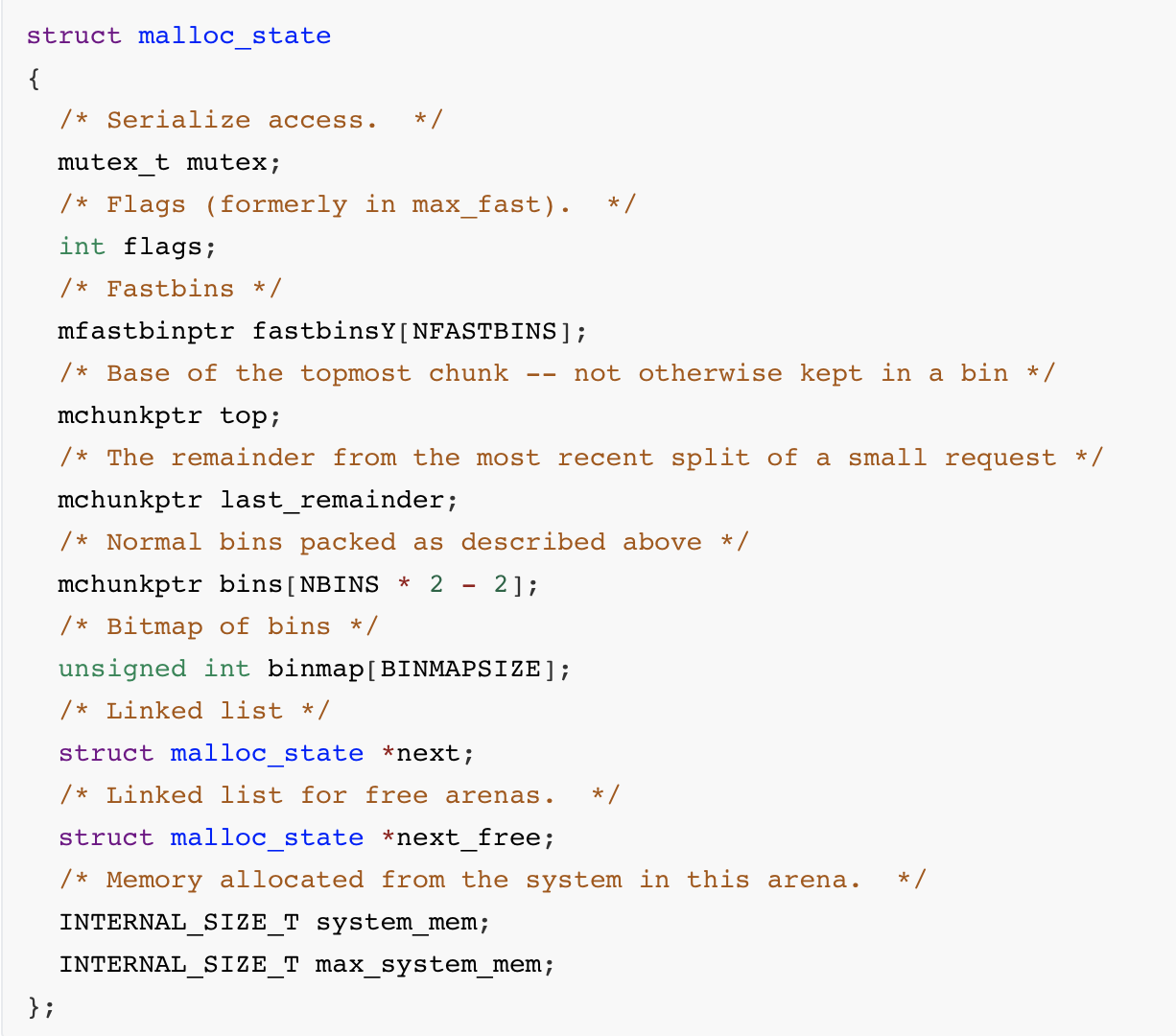
bins
fastbin
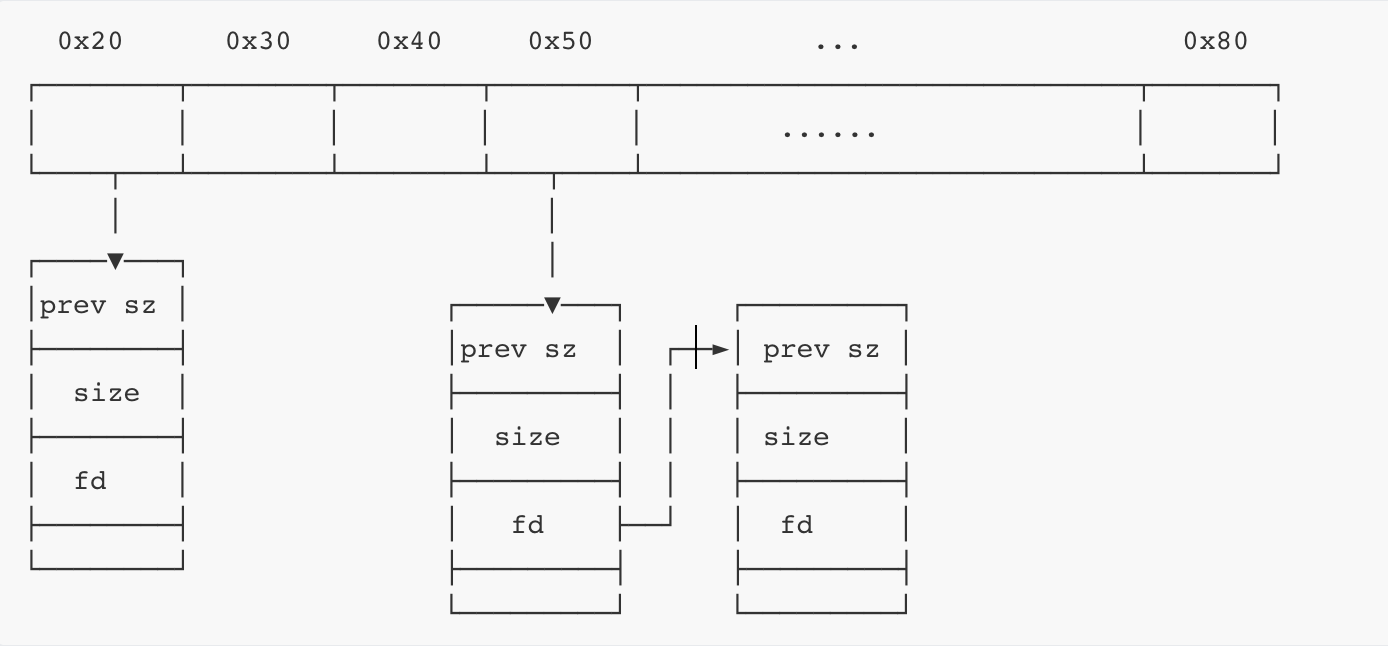
①管理fastbin free chunk,单链表结构,FILO(最后一个进入fastbin链表的,会被放在头部)。
②总共有10个fastBin链表,每个链表中fastbin的size一样,0x10递增。
③大小属于fastbin的chunk被free掉时,不会改变nextchunk的previnuse位,也就是说不会被合并。
unsortedbin
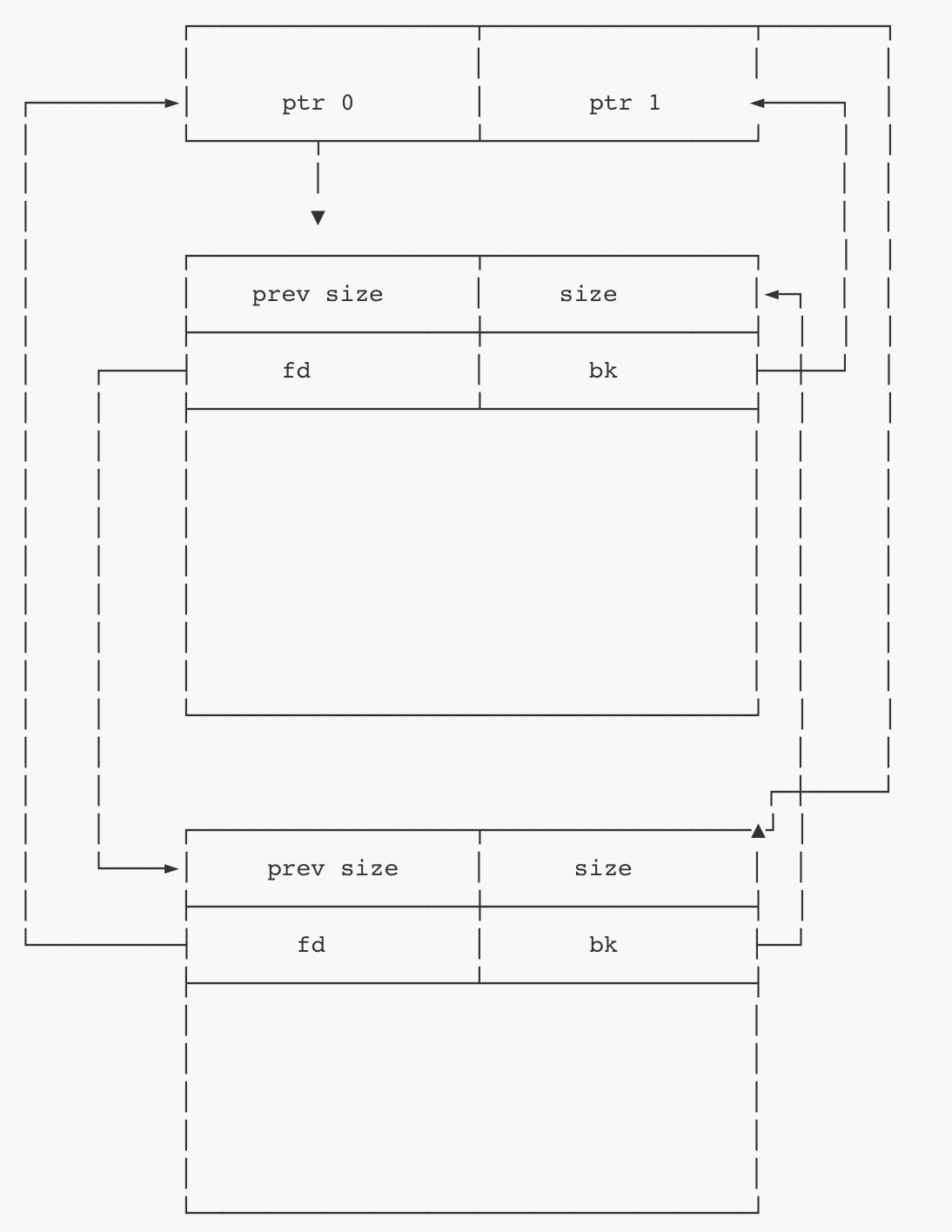
①管理unstorted chunk,只有一个双向链表
②所有大小大于fastbin的chunk都会先被暂时放入unsortedbin中,链表中的chunk大小不一。
smallbin
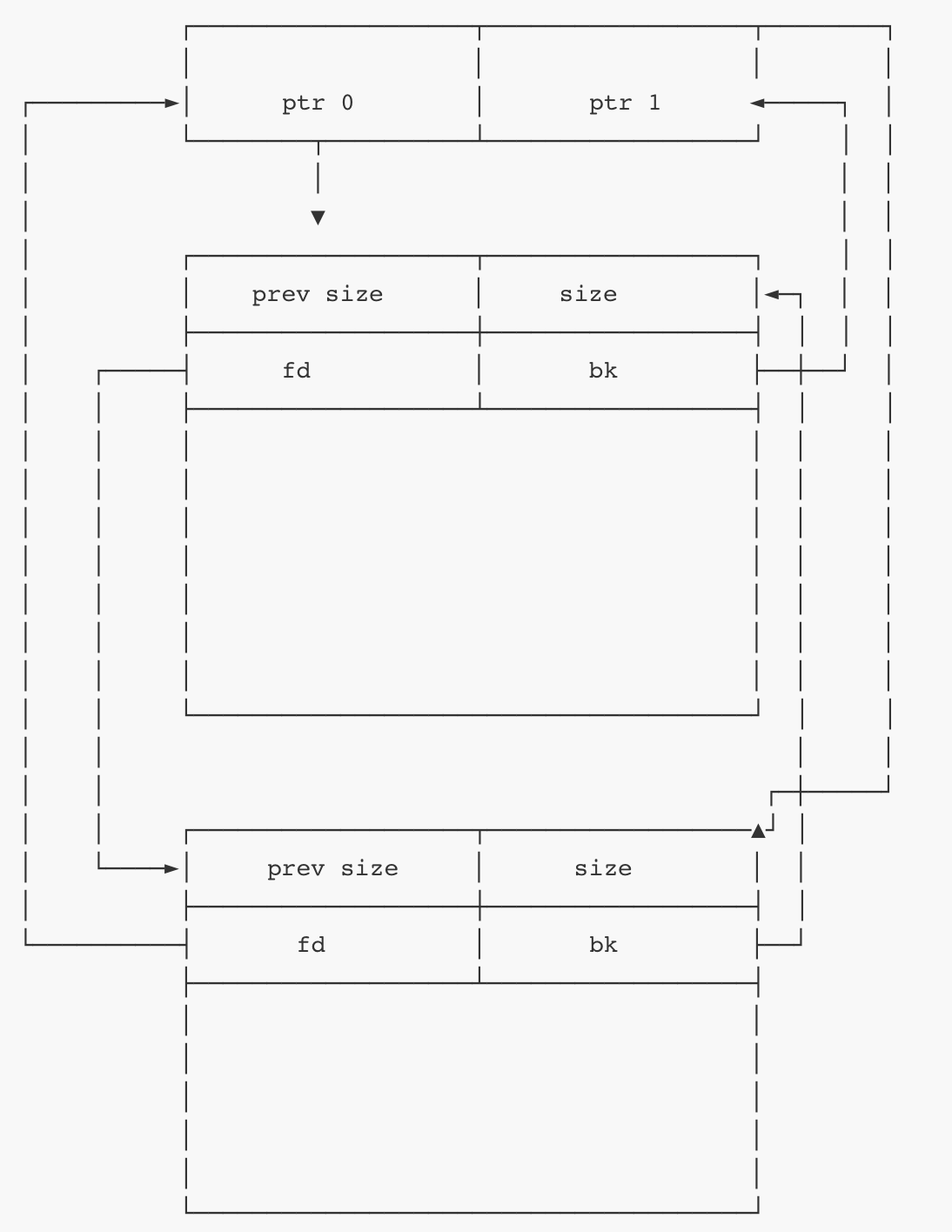
①管理small chunk,由62个双向链表组成,每个链表中的chunk大小不一样,大小以0x10 递增。
Largebin
①管理large chunk,63个双向链表,FIFO。
②同一个双向链表中chunk大小可以不一样,但是在一定范围内,bins大小从小到大排列。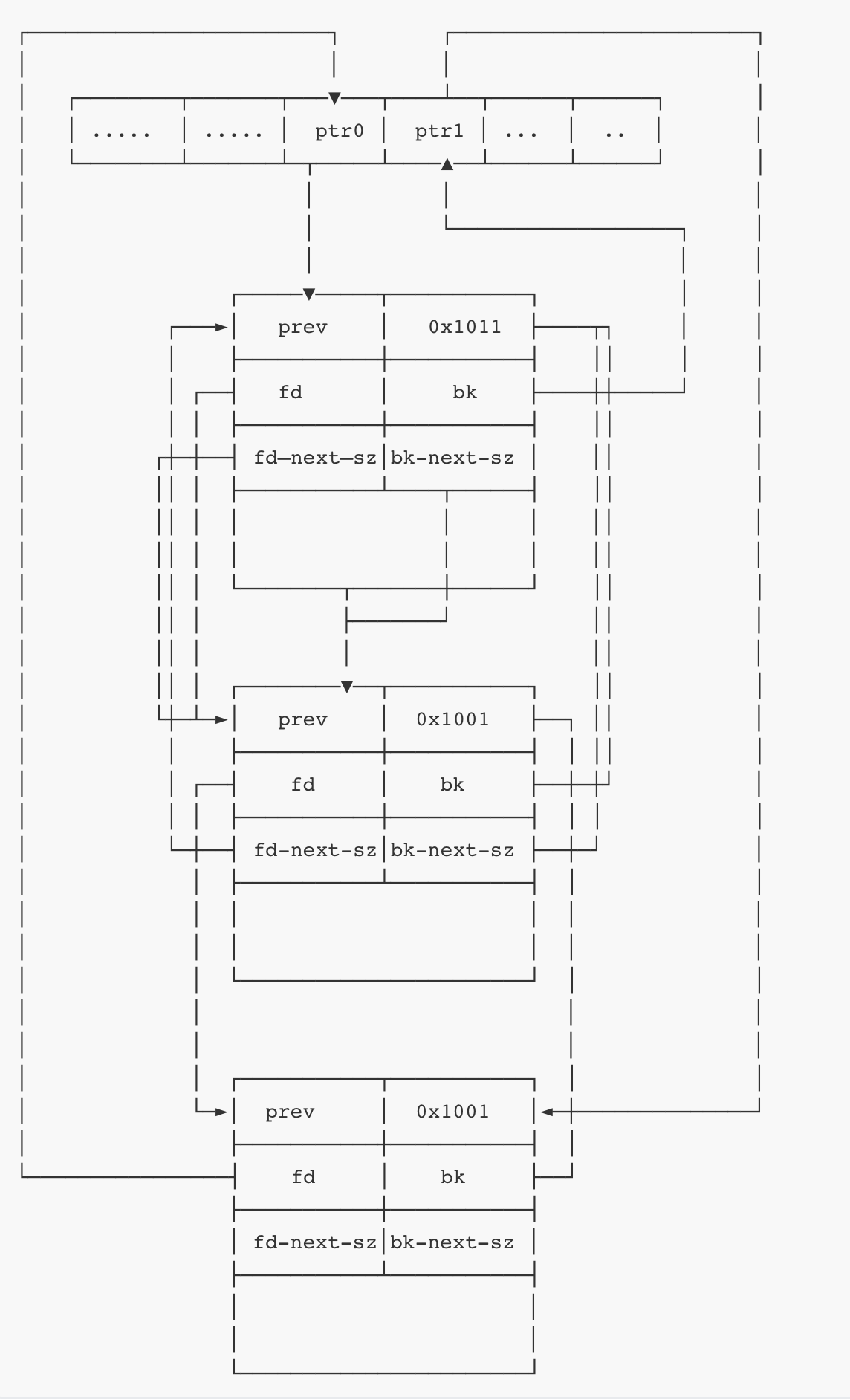
当我们调用malloc时,程序都干了什么
(1)计算堆块的真正大小(加上头部长度,对齐)
(2)是否在fastbin范围内?
①是,检查对应的bin链表中有没有chunk。
②有,分配给用户,完成。
(3)如果不在fastbin范围内,或者没有chunk可用。
(4)是否在smallbin范围内?
①是,检查对应大小的bin链表中有没有chunk。
②有,取出来给程序,完成。
(5)如果不在smallbin范围内,或者smallbin里面也没有。
(6)unsortedbin中有没有chunk?
①有的话,从尾部取出第一个chunk,看看大小是否满足需求。
如果大小满足,切分后大小是否大于minisize?
大于,切分快,返回给用户,剩下的块放进unsortedbin。
小于等于minisize,直接返回给用户,完成
如果大小不满足,把这个快放入small/largebin对应的链表中,继续遍历下一块。
(7)如果unsortedbin中所有的块也不能满足需求。
(8)大小是否在largebin范围内?
①是,检查对应的bin表有没有符合的chunk。
有,找到了满足需求最小的chunk,切分快返回,剩下的放进unsortedbin中。
(9)largebin也不行,再次遍历small/large找best fit的chunk。
(10)还是没有,那就从topchunk中切割
(11)topchunk还不够?mmap系统调用。
当我们调用free时,程序都干了写什么
(1)free的chunk大小属于fastbin吗?是,放进fastbin,完成。
(2)是mmap分配吗?是,调用munmap回收,完成
(3)前一个chunk空闲吗?是,向前合并
(4)后一个chunk是topchunk吗?是,和topchunk合并,完成。
(5)后一个chunk是free吗?是,向后合并
(6)放进unsortedbin,完成。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!