Pwn入门系列1——汇编语言基础
一些量词
bit 比特 1位
byte 字节 8位
word 字 16位
dword 双字 32位
qword 四字 64位
计算机寻址方式
① 当前主流操作系统中,都是以字节为寻址单位进行寻址
②意味着计算机访问的最小单位是一个字节
前言
①计算机并不能直接运行高级语言
②我们编写的高级语言程序需要进行编译后才能在计算机上运行
③高级语言经过编译之后,经过编译器处理,被打包成一个可执行文件的格式
④那么,计算机真正能够被运行的是什么
机器码——0和1
①深入底层后,计算机其实很笨,只能完成一些很基本的操作,但是速度很快。
②机器码就是一个个0和1组成的,为了方便人类的阅读,一般都以16进制呈现。
③尽管如此,一个个16进制字符可读性仍然很差
④汇编语言就是把这些及其指令代码以助记符的形式翻译一下,方便人类的阅读。
寄存器
①计算机的指令都是由CPU来执行
②在计算机系统结构中,CPU和内存是分开的。
③寄存器存在于CPU中,是CPU的直接操作对象。
寄存器种类
寄存器名称 作用 备注
RAX 通用寄存器 低32位:EAX ;低16位:AX;高8位:AH;低8位:AL
RBX 通用寄存器 同上
RCX 通用寄存器 同上
RDX 通用寄存器 同上
RDI 通用寄存器 低32位:EDI
RSI 通用寄存器 同上
R8 通用寄存器 低32位:R8d;低16位:R8W;低8位:R8B
R9 通用寄存器 同上
R10 通用寄存器 同上
R11 通用寄存器 同上
R12 通用寄存器 同上
R13 通用寄存器 同上
R14 通用寄存器 同上
R15 通用寄存器 同上
寄存器
①上述的通用寄存器,通常用于参数传递以及算数运算等通用场合
②RSP为栈顶指针,RBP为栈底指针,二者用于维护程序运行时的函数栈
③EFLAGS为标志位寄存器,用于存储CPU运行时计算过程中的状态,如进位溢出等。
④RIP指针用于存储CPU下一条将会执行的指针,不能直接修改,正常情况下会每一次运行一条指令自增一条指令的长度,当发生跳转时才会以其他形式改变其值。
寻址方式
寻址方式 示例 实际访问
立即寻址 1234h 1234h这个数字本身
直接寻址 [1234h] 内存地址1234h
寄存器寻址 RAX 访问RAX寄存器
寄存器间接寻址 [RAX] 访问RAX寄存器存储的值的这一内存地址
变址寻址 [RAX+1234h] 访问RAX寄存器存储的值+1234h这一内存地址
汇编指令
①计算机只能完成很基本的操作。这些操作大多是对一些寄存器的值进行修改
②这些指令通过排列组合,完成复杂的功能
③两种格式Intel和AT&T
④二者的差别主要在于源和目的操作数顺序上
⑤可以通过立即数寻址来进行判断
汇编指令
指令类型 操作码 例子(intel格式) 实际效果
数据传送指令 mov mov rax rbx rax=rbx
取地址指令 lea lea rax [rbx] rax=&*rbx
算数运算指令 add add rax rbx rax=rax+rbx
sub sub rax rbx rax=rax-rbx
逻辑运算指令 and and rax rbx rax=rax&rbx
xor xor rax rbx rax=rax | rbx
函数调用指令 call call 1234h 执行内存地址1234h处的函数
函数返回指令 ret ret 函数返回
比较 cmp cmp rax rbx 比较rax与rbx,结果保存在EFLAG寄存器
无条件跳转 jmp jmp 1234h eip=1234h
栈操作指令 push push rax 将rax存储的值压栈
pop pop rax 将栈顶的值赋值给rax,rsp+=8
汇编指令
①不难发现两个操作数指令的目的寄存器都是第一个寄存器
②call和jmp指令看起来效果一样,但是描述却有些不同
③call的话是调用,需要一些函数地址的保存压栈参数传递的操作
④jmp指令类似于函数中的if else语句,只设计跳转,不能作为函数调用来使用
⑤另外在pop时rsp是+8而不是-8
汇编指令
①计算机在执行汇编代码时,只会顺序执行
②通过call、jmp、ret指令来完成跳转
③所有汇编指令代码的执行流并不像高级语言程序一样流程明确
④汇编代码的经常性跳转会导致可读性差
汇编指令
比如:
1 | int a=0 |
翻译成汇编
1 | mov rax,0 //int a=0 |
汇编指令
①这里的jge是通过eflag寄存器中的标志位来判断
②而eflag标志位是通过cmp来设置
示例
①int a,b //存放于rax和rbx中
②两种swap方式:
第一种:int c=a;a=b;b=c
第二种:a=a+b;b=a-b;a=a-b;
深入到汇编
①第一种方式相当于:
mov rcx rax;
mov rax rbx;
mov rbx rcx;
②第二种方式相当于:
add rax rbx;
mov rcx rax;
sub rcx rbx;
mov rbx rcx;
sub rax rbx;
对比
①从高级语言层面看:
第一种方式申请了一个变量c,第二种直接在原本的变量上操作
②从汇编语言层面上看:
第一种指令数少,而第二种方式涉及到算术运算指令。
③从结果上看,可以直接:xchg rax rbx
在CTF中需要掌握到什么程度
①能看懂就行,绝大多数情况下不需要真正的编程(shellcode题目除外)
②IDA F5有时候不需要读汇编
③通常都是分析gadget,知道怎么用
④调试程序也不需要分析每一条汇编指令,单步执行然后查看寄存器状态即可。
⑤但是必须得会汇编,学PWN必须得会汇编
数
①数学是科学的基石,任何科技都离不开数学的支撑
②在计算机中,无论数据是以二进制或者十六进制十进制表示,本质上都是代表一个数
③尽管数据在计算机内部有很多存储形式(补码、原码、反码等)。但是本质上都是数。
数
计算机不能存储无限大的数,这个数的数值有一定的上限和下限。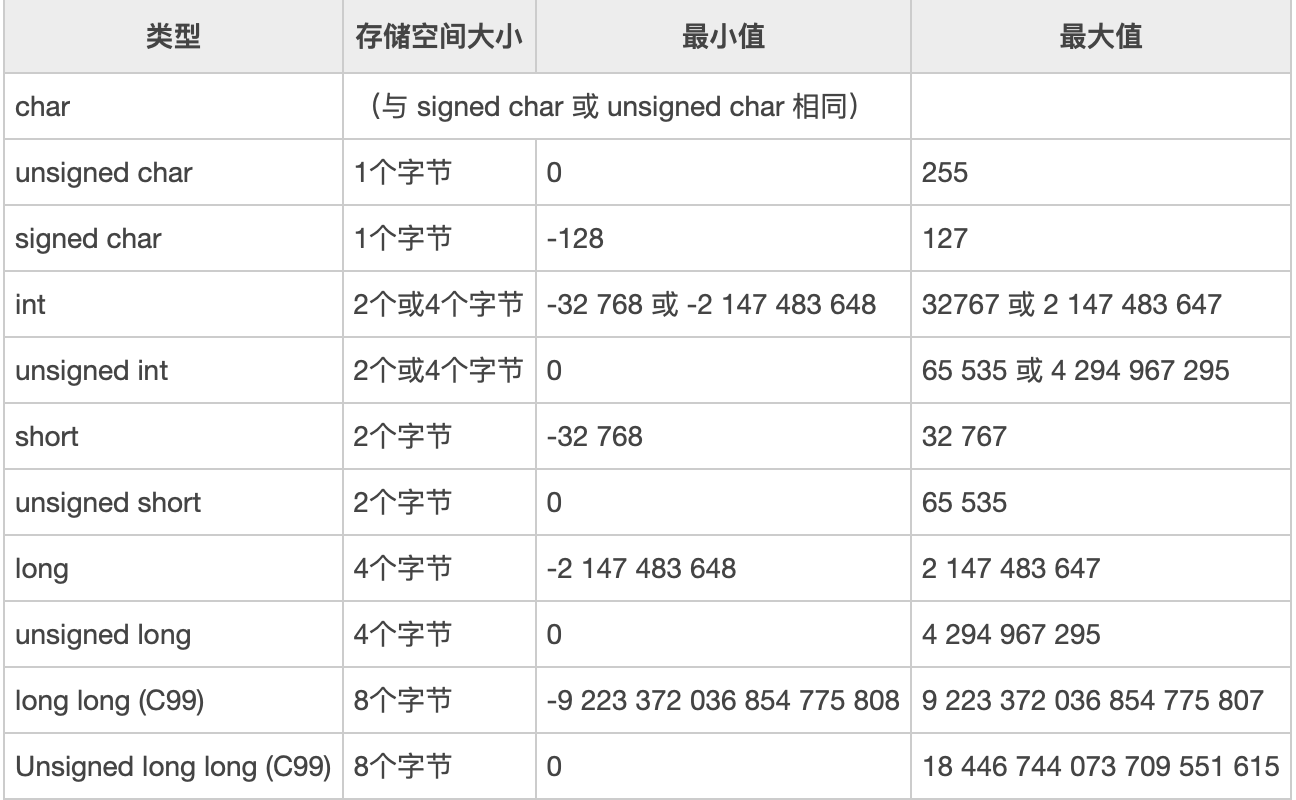
数
①如果是Unsigned也就是无符号数,数据的每一位都是代表数据。
②如果是signed有符号数,那么数据的最高位会被当做符号位处理。
③0代表正数,1代表负数。
溢出
①数值有上下限范围,那么就不可避免的会有溢出情况
②以32位int为例,有以下四种溢出:
无符号上溢:0xffffffff+1变成0
无符号下溢:0-1变成0xffffffff
有符号上溢:有符号正数0x7fffffff+1变成负数0x80000000
有符号下溢:有符号数0x80000000-1变成正数0x7fffffff
溢出
这就是整数溢出,原因如下两点:
①存储位数不够
②溢出到符号位
整数溢出一般配合别的漏洞来使用。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!